EFK 구축 후기 - 2편
EFK 구축후기 1편에 이어서.. 작성!!
kibana 날짜 문제

kibana를 보니, 해당 날짜로 index를 생성해서 로그를 수집하다보니 항상 오전9시부터 로그가 있다는 것을 알게 되었다.

잘 안보이긴 하지만, 전날(26일) index를 보면 27일 0시~9시까지의 로그가 존재하는 것을 확인할 수 있다.
logstash_foramat을 이용하여 index를 생성하다 보니 날짜 부분을 신경쓰지 못했는데, 원인을 생각해보니 다음과 같았다.
로그의 timestamp : UTC+9
kibana : UTC+9
index name : UTC+0
사진을 보면 알겠지만, kibana의 시간은 지금 UTC+9로 되어있고, index format은 UTC+0으로 되어 있어서 발생하는 문제였다.
일단, 임시로... UTC+0인 필드를 새로 생성해서 UTC+0과 UTC+9필드를 2가지 만들어놔서, timestamp를 설정할 수 있도록 옵션을 주었는데, 더 좋은 방법이 있을것이다. 생각나면 수정!!(예정)
Fluentd vs Fluent-bit
무엇을 사용해야할까!!!
정답은 나도 모른다.
가장 일반적인 관점에서 비교를 해보자면 Fluentd는 ruby로 작성되었고, Fleunt-bit는 C로 작성되어 가볍고, 좀 더 좋은 퍼포먼스를 보일 수 있다는 점이다.
반면, Fluentd는 대용량의 데이터를 처리하는 데 특화되어 있다.
이건 뭐 인터넷 어디에나 볼 수 있는 내용이고, 직접 EFK를 구축해보면서 느꼈던 Fluentd와 Fluent-bit의 차이점을 적어보겠다. 개인적인 생각이니, 틀린 부분도 있을 수 있다!
외부 플러그인 vs 내부 플러그인
Fluentd의 경우에는 생각보다 외부 플러그인에 의존해야 하는 경우가 많을 것이라고 느꼈다.. 외부 플러그인을 사용하면 우선 Dependency를 고려해야한다. (ruby gem)
물론 공식 문서에 관련 외부 플러그인 링크도 있고 하지만, 역시 찾기?가 힘든 느낌이고, 오픈소스 사용에 익숙하지 않으면 불편할 것 같았다. 굉장히 이용할 수 있는건 많지만 활용하기 어려운 느낌이다.
반면 Fleunt-bit은 플러그인의 수가 Fluentd보단 적지만, 제공하는 내부 플러그인이 사용자 친화적인 것을 느꼈다. 한 가지 예를 들자면, elasticsearch 플러그인의 replace_dots 기능... 그리고 공식 문서가 좀 더 잘되어있는 느낌이 들었다.
무시할 수 없는 생태계 차이
이게 무슨 말이냐면... 1편에서 적었던 내용인데, 중첩된 구조의 필드에 접근할 때 사용했었던 record_accessor를 사용하면서 들었던 생각이다.
fluent-bit에서는 특정 플러그인을 제외하면 다른 플러그인에서 사용할 수 없는 불편한 점이 있었고, 이 사안은 github 이슈가 몇년째... open 되어있다... 실제로, 아직까지 불편함을 겪고 있는 사용자가 많지만, 기여자가 적어 신경 쓸 겨를이 없는 것 같다. 그리고 이 문제는 어쨌든 lua script로 해결할 수 있는 문제이기 때문인 것 같아서, 빨리 고쳐지지 않는 것 같다.
이런 기술적 지원 부분에서는 Fleuntd가 좀 더 우위에 있다는 느낌이 들었다.
Fluentd & Fluent-bit 두개를 합친다면?
아예 뜬금없는 이야기가 아니라, 실제로도 많이 사용하는 아키텍처이기도 하다.
Fluent-bit와 Fluentd는 상호 배타 관계가 아니기 때문에 서로의 부족한 점을 보완하여 사용할 수도 있다!
실제 로그 수집과 파싱을 Fluent-bit이 데몬셋으로 진행하고, 집계와 라우팅을 Fluentd로 하는 구조를 사용하기도 한다.
어떤 장점이 있을까?
- 데몬셋으로 여러 노드에 생성되는 Pod는 가벼운 Fluent-bit로, 집계와 라우팅은 많은 데이터를 처리할 수 있는 Fluentd로 안정적인 구조를 구축할 수 있다.
- 서로의 장점만 취하여 원하는 요구사항을 쉽게 구현할 수 있다.
- 다양한 문제 상황에 유연하게 대처가 가능하고, 단독 사용에 비해 확장성이 좋다.
- 로그 수집 과정에서 과도한 부하를 막을 수 있다.
적다보니 1,4와 비슷한 맥락이고 2,3과 비슷한 맥락이다..
1,4에 대해 설명하면 예를 들어, Fluent-bit로 수집, 파싱, 라우팅을 진행하게 되면 많은 데이터를 처리하지 못해 발생하는 문제인 backpressure 문제를 마주칠 수 있다.
backpressure은 간단하게 설명하자면, 나가는(flush) 데이터(라우팅)보다 들어오는 데이터가 더 많아 데이터의 손실이 발생하는 문제이다.
데몬셋으로 각 노드에 배포되는 수집기는 가벼운 Fluent-bit로, 다양한 source에서 수집되는 데이터를 처리하고 집계, 라우팅 하는 것은 많은 데이터를 처리할 수 있는 Fluentd가 담당하여 이러한 문제를 해결할 수 있다.
내가 Fleunt-bit & Fluentd 구조를 택한 것도 이러한 이유로 인해서이다.
부하테스트 이야기
첫 번째 목표이기도 했던 부하테스트를 이용한 두 스택의 비교...는 사실 진행하지 못했다.
우선 도구는 오픈소스인 nGrinder를 도커로 로컬환경에서 사용하였다.
도커 이미지로 제공되다보니, 로컬에서는 정말 간편하게 설치할 수 있었다. (다만, 쿠버네티스 온프레미스 환경에서 배포하는 건 생각보다 어렵다.. 지금 진행하고 있는데, 방화벽 때문인지 Controller와 Agent간의 통신이 안된다.. 해결하면 해당 내용으로 포스팅하는걸로.)
아무튼, 부하테스트를 진행을 해 보았는데 생각보다 지표가 너무 안좋고 결과가 굉장히 불안정하게 나왔다.
지금 생각해보면 당연한거지만, 내가 부하테스트를 진행하는 컴퓨터의 네트워크 환경에 굉장히 큰 영향을 받고 있었다.
tps그래프를 봐도 굉장히 불안정하고, 성능도 나오지 않았다.
왜 그런가.. 처음에는 답답했는데, 우연히 작업관리자의 네트워크 처리량 그래프와 ngrinder의 실시간 tps그래프를 보고 알게 되었다.
두 그래프가 거의 일치하였다.
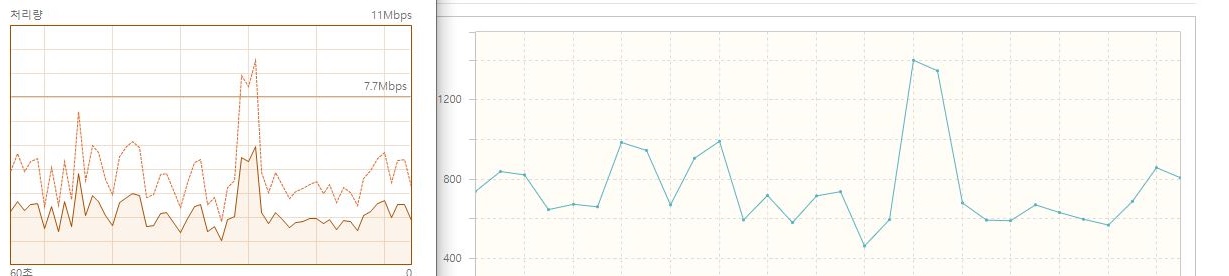
이 말은 즉, 부하테스트의 target 서버의 영향을 받지 않고, 단순히 클라이언트 컴퓨터의 네트워크 환경에 따라 결과가 달라진다는 의미다.
내가 지금 온프레미스 클러스터에 ngrinder를 배포하는 것도 이러한 이유 때문이다..
부하를 어떻게 줄일까? - flush_interval
buffer 관련 플러그인에서 flush_interval 의 시간대로 buffer에서 flush 작업이 이루어진다.
flush_interval이 짧을수록, 실시간으로 많은 데이터를 처리할 수 있겠지만, 리소스 사용량이 증가한다.
해당 내용은 Grafana Dashboard에서도 확인할 수 있었다.
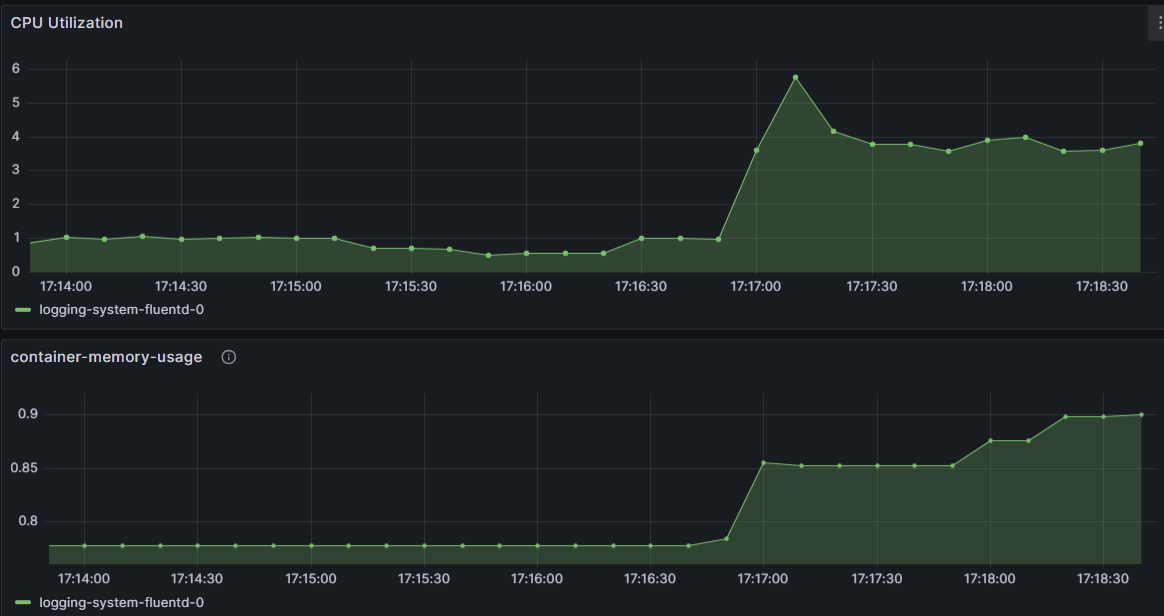
이거에 대해서 왜 생각을 해봤냐면, fluent 보다도 순간적으로 많은 부하를 받는 것이 바로 elasticsearch였다.
그래서, 전체적인 부하를 줄일 수 있는 방법에 대해서도 생각을 해보게 되었다.
이를 통해 기대하는 효과는 다음과 같다. (부하테스트를 진행할 수 있는 환경이 갖춰지면 한번 검증해 볼 예정이다.)
- tps 증가 (빠르게 flush하여 backpressure 문제 완화)
- 1에 따라 error 수 감소
- elasticsearch의 리소스 사용량 감소 (한번에 많은 데이터가 들어가지 않고, 짧은 주기로 여러번 flush하여 elasticsearch의 부하를 감소시킨다.)
Memory vs Filesystem
fluent-bit / fluentd의 경우 데이터를 버퍼링 하는 2가지 옵션(storage.type)을 제공한다.
- In-memory 방식인 Memory
- Disk에 백업하는 Filesystem
역시 backpressure 문제를 완화하기 위해 이러한 옵션을 제공한다.
버퍼 메모리가 부족한 경우, data chunk가 flush 될 때까지 INPUT 플러그인이 잠시 중단되고, 아래와 같은 로그 메시지를 보낸다.
[ info] [input] tail.0 resume (mem buf overlimit)
[ warn] [input] tail.0 paused (mem buf overlimit)
[ info] [input] pausing tail.0
사용중인 INPUT 플러그인에 따라 데이터의 손실이 발생할 수 있으며, tail 플러그인의 경우 마지막 파일의 위치를 기록하는 특성 때문에, 데이터 손실이 발생하지 않는다.
다음은 관련 옵션을 정리해보았다.
옵션 - 공식문서
Mem_Buf_Limit : INPUT에서 기록되는 메모리의 양 제한 (더 많으면 ingest(주입)되지 않음)
서비스의 안정성을 위함→ 이 방법은 데이터의 손실 우려가 있음
storage.max_chunks_up : 메모리에 있을 수 있는 chunk의 개수 조절 (기본 128개), Filesystem 을 사용하므로 Mem_Buf_Limit 설정은 효과가 없게 됨
stroage.backlog.mem_limit : 전달되지 않은 스토리지 계층에 있는 데이터 청크 개수, 모든 청크의 현재 메모리 사용량과 비교하여 현재 제한보다 적은 메모리를 소비하는 경우, 백로그 청크를 메모리로 가져와 출력으로 전송(기본 : 5M)
storage.backlog.mem_limit : 내보내기 전의 가지고 있을 수 있는 chunk 용량
storage.total_limit_size : fluentbit는 버퍼링에서 논리적 queue 사용해서 다양한 target으로 라우팅 된다. target마다 다른 속도에 따른 backpressure 발생을 막기 위한 청크의 양을 제한한다. (가장 오래된 청크가 삭제됨)