ETL 이란 무엇일까?
- E (Extract) : 대상 소스에서 데이터를 추출
- T (Transform) : 원시 데이터를 반환하여 목적에 맞는 형태의 데이터로 변환
- L (Load) : 변환한 데이터를 목표 시스템에 적재
간단하게 설명하면, "입맛대로 데이터를 뽑아내고 변환하여 저장하는 것!"
그럼 ETL은 왜 필요한걸까?
간단하게 2가지 이유를 들어보자면,
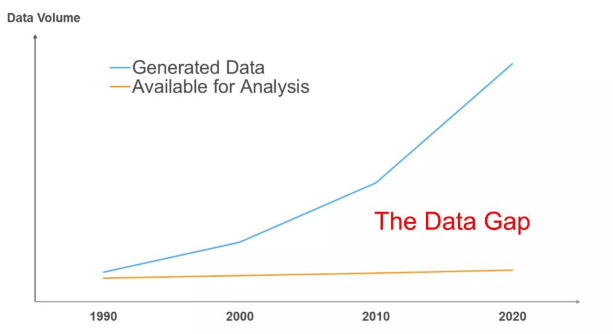
- 데이터 분석에서 ETL에 많은 시간이 소모되며, 어려움을 겪고 있음
- 초연결사회에서 발생하는 수많은 데이터와 활용할 수 있는 데이터의 차이가 벌어지는 현상
이를 잘 나타내는 표가 있어서 첨부하겠다.
그렇다면 이제 AWS Glue에 대해 알아볼 차례이다..
AWS Glue의 정의는 다음과 같은데,
분석, 기계 학습(ML) 및 애플리케이션 개발을 위해 여러 소스에서 데이터를 쉽게 탐색, 준비, 이동 및 통합할 수 있도록 하는 확장 가능한 서버리스 데이터 통합 서비스
여기서 서버리스 개념에 대해 헷갈리는 분들이 계실 것 같아 정리하겠다.
서버가 필요없다는 뜻인가?
그건 아니고...
서버리스란?
- 서버 관리가 필요없으며
- 따라서, 빠른 배포가 가능하고 트래픽의 변동에 유연하며
- 사용량 또는 실행 시간에 따른 요금이 부과되고
- 이벤트 기반 작동 방식을 가진다.
이러한 특징을 가진 서비스라고 생각하면 되겠다!
그러면 많은 ETL 도구 중에 왜 AWS Glue 를 사용하는 것일까?
- 서버리스 컴퓨팅 방식으로, 작업에 들어가는 비용을 최소화할 수 있음(AWS Glue Auto Scaling)
- AWS Glue Studio를 이용한 no-code 방식의 ETL작업을 진행할 수 있음 → 빠르고 쉬운 구축
- 이벤트 기반 → 다양한 AWS의 리소스와 결합하여 ETL 프로세스를 구축할 수 있음
- Data Catalog 지원하여 효율적으로 데이터를 모니터링하고 관리할 수 있음
- crawler 통한 자동 스키마 검색 / 변경된 스키마에 대한 탐지와 버전 관리 가능
- 스크립트 이용한 데이터 변환(PySpark)
- 다양한 데이터 스토어에 대한 접근성
Data Catalog: 사용자가 필요한 데이터를 빠르게 찾을 수 있게 도와주는 메타데이터 및 관련 정보를 관리와 검색을 제공하는 시스템
지금 당장 이러한 장점들이 이해가 안가는 것이 당연하다.
직접 사용해보면서 느낄 수 있는 장점이 많기에, 사용해보면서 이러한 장점들을 몸으로 느낄 수 있을 것이다..
AWS Glue Architecture

간단하게 구조에 대해 설명해 보자면
- Data Stores에 crawler가 접근한다.
- crawler는 Data의 Schema를 파악하여 Data Catalog를 생성해낸다.
- 사용자는 Data Transform 을 하는 일종의 Job을 생성한다.
- script로 작성된 job은 Data Source에서 추출(Extract)해낸 Data들을 변환(Transform)한다.
- job은 스케줄링 되어 일정 주기마다 실행되거나, 특정 AWS Resource의 Event로 인해 Trigger된다.
- 변환(Transform)한 Data들을 Target에 저장한다. (S3, RDB 등)
AWS Glue 실습 주의사항
실습하기 전에 먼저 주의사항에 대해 알아보자!
(이런 것들이 있다고 읽고 넘어가서.. 문제가 생기거나 하면 다시 되돌아와서 봐도 좋다.)
- S3 기준 스키마가 다른 파일은 다른 폴더에 위치해야 한다.
- 크롤러 IAM 및 S3 정책을 올바르게 설정해야 한다.
- 같은 스키마의 데이터가 여러개 있으면 해당되는 하나의 메타데이터만 생성된다.
- 크롤러의 옵션 중에 ‘Parameters’를 ‘Recrawl new only’로 설정하면 이전 스캔했을 때의 폴더를 재방문하지 않는다. (스키마가 다른 새로운 데이터를 추가할 시에는 이전 스캔에 없던 경로로 추가해야함)
- 가장중요! 과금이 생각보다 세게 나온다... (굉장히 강력한 대신, AWS 리소스 중에선 비용이 많이 나가는 편이다.)
AWS Glue 실습 프로세스

실습 절차 (설정)
- json 파일을 업로드 할 S3버킷을 생성 후에, 버킷 정책을 설정해준다.
- 버킷의 계층구조를 crawler가 탐색할 수 있게 생성한다.
- AWS Glue crawler를 설정한다. (crawler 설정에 다음 하위 항목이 포함되어 있으므로, 자연스럽게 같이 설정할 수 있다.)
- crawler의 IAM 역할을 생성한다.
- Data catalog를 저장할 DB를 생성한다.
- AWS Lambda 관련 설정을 진행한다. (crawler를 trigger 하기 위함)
- Lamda의 Glue 접근 권한
- Lambda trigger, prefix, suffix 설정(optional)
- Lambda가 실행할 function script 작성
Lambda 사용 시에 주의해야할 점
바로 Recursive invocation(재귀 호출)이다.
이 부분은 실제, Lambda Event를 S3로 설정하였을 때 문구로도 사용자에게 각인시켜 주는 부분이다.

다음과 같은 과정으로 무한으로 Lambda function이 실행될 수 있다.

실제 이번 실습은 S3버킷의 객체가 upload 되는 것을 trigger로 설정하기에, 이러한 재귀 호출을 조심하여야 한다.
재귀호출을 방지하는 방법 중 가장 깔끔한 것은, Input Bucket과 Output Bucket을 따로 설정해 주는 것이다.
또한, s3 버킷의 계층구조와 suffix과 prefix를 설정하여, 특정 조건에만 Lambda function이 실행되게 할 수 있다.
필자는 이런식으로 계층 구조를 생성하였다.

다음은 실습에서 사용할 Lambda function Code이다.
해당 코드를 참고하여, s3 object upload를 crawler trigger로 설정해 보자.
import json
import boto3
client = boto3.client('glue')
def lambda_handler(event, context):
for record in event['Records']:
object_key = record['s3']['object']['key']
# origin_data/log_data로(경로) 시작하는 개체인 경우에만 크롤러 실행
if object_key.startswith('origin_data/log_data'):
print('--------- crawler start! ---------')
response = client.start_crawler(Name='Demo-Athena-log-crawler')
# 파일 이름 추출
file_name = event['Records'][0]['s3']['object']['key']
print('raw_data: ', file_name)
print(json.dumps(response, indent=4))
여기까지 진행을 마쳤다면, ETL을 할 준비를 마친 것이다! (준비가 좀 힘들었지만, 다음 과정은 훨씬 간단하다.)

이제 ETL 을 해보자!
Data를 가공하기 위해선 보통, Spark를 이용하는 편인데, 우린 Spark를 모른다.
그럼 어떻게 하느냐?
친절한 AWS가 알아서 다 해준다. (돈만 준다면...)
바로 Visual ETL 을 이용하여 코드 없이 ETL 구축이 가능하다!

필요한 작업을 끌어다 놓고, 잇고, 설정만 진행해주면 ETL 끝이다!
내가 끌어다 놓은 작업들은 모두 Pyspark 코드로 자동으로 작성되므로, 얼마나 편리한 기능인가!


또한 job 별로 대시보드를 제공하여 ETL job에 대한 결과를 시각적으로 제공한다.

크론식을 이용한 job 스케줄링을 제공하여, 원하는 시각에 주기적으로 job을 실행시킬 수 있다.
Trouble shooting
데이터 저장소의 변경 상황에 맞는 스키마를 업데이트 or 업데이트x를 원한다면 crawler의 Advanced Option을 살펴보자.

그리고, CSV 파일을 이용하여 실습을 진행할 경우, 해당 이슈를 고려해야 한다.(2023.12 확인됨)
데이터의 모든 열이 모두 string인 경우에 Glue가 머리 행(column)을 인식하지 못하는 문제
해결 방법은 다음과 같다.
- 자료형이 String인 열 외에 다른 자료형을 가진 열 추가
- 사용자 지정crawler classifier 정의하기
AWS Glue는 비전문가도 쉽게 ETL을 구축할 수 있다는 점에서 굉장히 큰 이점과 강력함을 갖고있다.
그러나, 역시 비용 문제... Cloud computing service를 이용하면 반드시 고려해야할 부분이다.
단기간에 ETL을 구축해야 하는 상황이면 굉장히 강력한 도구라고 생각되지만,
개인 사이드 프로젝트나 공부용으로는 비용 문제 때문에 사용하기 어렵다고 생각한다.
정말 간단하고 적은 용량의 data로 ETL job을 몇번 실행 시켜도, 몇만원이 나오는 무서움을 맛볼 수 있을것이다....
'Public Cloud (AWS, GCP)' 카테고리의 다른 글
| AWS Cloudfront 맛보기 (1) | 2024.02.11 |
|---|---|
| AWS S3 맛보기 (0) | 2024.02.11 |

